The room, the brief, and the first decision
MIT Reality Hack runs for 36 hours. That is not a lot of time. You get a brief — open, deliberately so — and a piece of hardware, and you are expected to build something meaningful for spatial computing. In January 2026, the hardware was Snap Spectacles Gen 5. The brief was: show us what is possible.
The team sat with that for about an hour. We had used Spectacles before. We had shipped Ice Fishing and Timely on the platform. We knew the hardware's constraints: hand tracking only, no keyboard, no mouse, a waveguide display sitting in front of both eyes. We also knew its actual capability: persistent spatial anchors, a full spatial computing SDK, voice input, and a FOV that lets you look at the world and overlay information on it at the same time.
The decision that shaped everything came early: we were not going to replicate a desktop workflow in glasses form. That is the obvious thing to build, and it is almost always wrong. We wanted to find something that could only exist in this form factor.
I said: what does AI look like when you never have to pick up a phone?
That question became Noodle.
The problem we were actually solving
There is a failure pattern in how AI tools are designed right now. Every single one of them requires a context switch. You are working on something. You have a question, or a half-formed idea, or something you want to explore. You stop what you are doing. You pick up your phone or move to your laptop. You open an app or a browser. You type a prompt. You read the result. Then you go back to what you were doing, carrying the answer in your head, hoping you have not lost the thread of the original thought.
That context switch is not a minor inconvenience. For creative professionals, it is the moment the work stops. The physical act of reaching for a device signals to your brain that you are now doing something else. The flow breaks. The idea dims a little. And AI tools that are supposed to accelerate creative thinking are, in practice, constantly pulling you out of it.
Smart glasses remove the reach. You do not pick up anything. The AI is already where you are looking.
This is what hands-free AI on a device with a spatial display actually unlocks: the ability to think out loud without stopping. You are at your desk with a sketch in front of you. You look at it. You say something. The system responds in your field of view, overlaid on the thing you are already looking at. You never left the moment. That is not a feature. It is a fundamentally different relationship between a person and a tool.
We called the pattern "the Toggle Tax": the cognitive cost of switching between contexts. Every switch taxes your attention. Remove the switches and you get something that feels less like software and more like a thinking partner.
What we built
Noodle is a spatial AI workbench. The name is a play on "noodling" — the act of thinking something through, turning it over, letting it develop. It is not a cooking application.
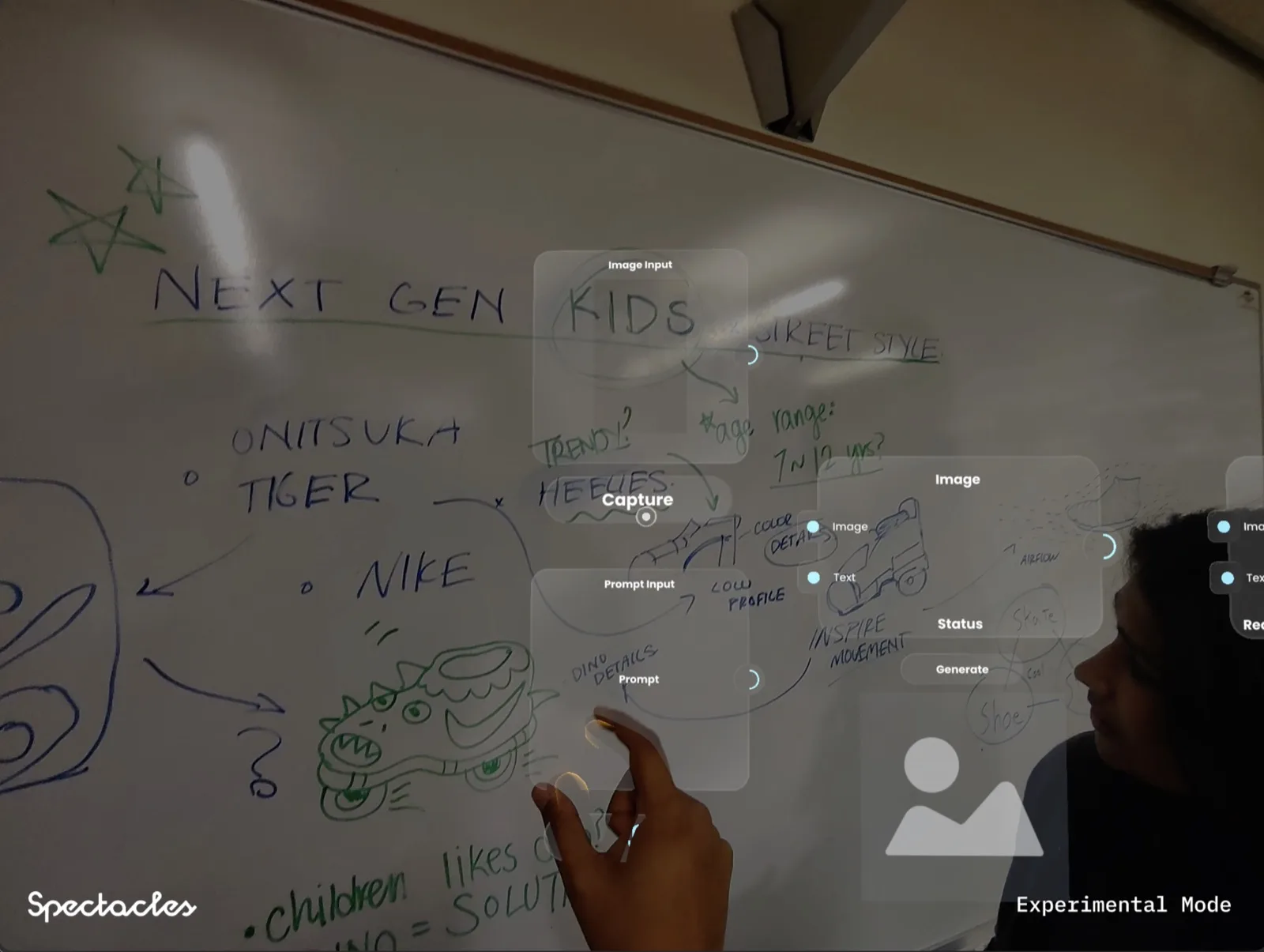
Here is what you see when you put on the glasses. In your field of view, floating above your real desk, is a node-based canvas. Nodes are connected by wires. Each node is a step in a pipeline: input, processing, output. You can create a node by pointing and pinching. You can wire two nodes together by dragging with your hand. The wires are not decorative. Drawing the connection actually triggers the pipeline.
The first input node is a camera capture. You look at a sketch on your desk — something you have drawn by hand on real paper — and the node grabs it. You connect that to a prompt node. You speak the prompt: "make this three-dimensional." You connect that to an output node. A 3D model of your sketch appears, placed spatially on your desk, sitting next to the paper it came from.
The whole flow happens in the space you are already in. You never looked at a screen. You never typed. You never opened a separate application. The idea-to-object pipeline completed in one continuous spatial session.
One detail that surprised us during the build: the act of wiring two nodes together felt like creative decision-making. On a keyboard-and-mouse interface, connecting an input to an output is a technical act. In space, with your hands, at desk scale, it felt like you were making the idea happen. The physicality of the gesture changed the emotional register of the tool.

Building on Snap Spectacles: what the platform actually gives you
We have built several experiences on Spectacles now. The platform's value is not the display. The display is impressive, but it is not the reason to choose Spectacles. The reason is the spatial computing SDK and the constraint set it imposes on you.
Spectacles has no keyboard. It has no touchscreen. Its primary inputs are hand tracking and voice. These are not limitations you design around. They are the reason the interface ends up being different from anything you would build for a phone or a laptop. Every time we have built for Spectacles, the hardware has forced us into a better design than we would have arrived at with an unconstrained brief.
For Noodle specifically, the platform gave us spatial anchors that held across the session, hand tracking precise enough to register a pinch gesture reliably, and a FOV wide enough that the node canvas felt like it was genuinely in the room rather than glued to the display. The voice input was essential: prompting by speaking is faster than typing for anything longer than a few words, and it keeps your attention on the physical world rather than pulling it down to a keyboard.
If you are thinking about what Spectacles makes possible for brands and activations, the fuller picture is at our wearables and smart glasses page. The Noodle build is the clearest argument we have for what spatial-native design actually means in practice.

What the 36 hours actually taught us
Hackathons are useful exactly because they remove the option of refinement. You build what you can build in the time you have, and you present that. The gaps between what you planned and what shipped are honest.
Three things from the build that stuck:
The result: three prizes, one question answered
Noodle won the Founders Lab Track Prize at MIT Reality Hack 2026 and the Best Use of Spatial AI prize, sponsored by Snap Spectacles. It also won the Snap Spectacles Community Challenge. Three prizes across 36 hours of work, from a panel that included researchers, platform engineers, and spatial computing practitioners who had seen every other build in the room.
The question that mattered to us was not whether we would win. It was whether the interaction model held up when strangers who had never seen Noodle put on the glasses for the first time. The answer was yes: the onboarding was intuitive enough that new users understood the node-and-wire system without being told, because the physical metaphor carried the logic. When the metaphor holds, the learning curve collapses.
That is the thing I want to leave you with if you are a brand team or a researcher who found this page. Spatial AI on glasses is not a future format. It is not a demo. We built it in 36 hours and it worked in front of judges who know the space. The interaction model is proven. The question is what problem it gets applied to next.
What this means for brands thinking about spatial AI
Noodle was built for a creative workflow, but the pattern it demonstrates is not creative-workflow-specific. It is a general answer to the question of what AI assistance looks like when it does not require a context switch. That question is relevant to any brand that has users who are doing something in the physical world and need information, guidance, or generation without stopping.
Consider: a technician on a factory floor who needs a diagnostic answer while their hands are occupied. A retail staff member who needs product information without stepping away from a customer. A designer who needs to iterate on a spatial concept while standing in the space it will occupy. The Toggle Tax applies in all of these contexts. Noodle demonstrated that you can remove it.
The studio's broader wearables work — including the live demos we have running at ar.rbkavin.studio — reflects the same design principle: spatial computing is most useful when it adds a layer to what you are already doing, not when it asks you to stop and engage with it on its own terms.
Noodle is open source. The full repo is on GitHub at github.com/rbkavin/noodle_creative_collab if you want to see how the node graph, spatial UI, and AI pipeline were built.
If you are thinking about what spatial AI could do for a specific user moment in your category, that is the conversation we want to have.
Frequently asked questions
Who won MIT Reality Hack 2026?
RBKAVIN. Immersive Studio won MIT Reality Hack 2026 with Noodle, a spatial AI workbench built natively for Snap Spectacles. The team took three prizes: the Founders Lab Track Prize, Best Use of Spatial AI sponsored by Snap Spectacles, and the Snap Spectacles Community Challenge. MIT Reality Hack is an annual spatial computing hackathon run out of MIT, drawing over 300 participants across teams of four to five, with a 36-hour build window.
What is Noodle and what does it do?
Noodle is a spatial AI workbench built for Snap Spectacles. It lets a creative professional sketch on their real desk, connect that sketch to an AI model using a node-based interface in their field of view, and receive a 3D model placed spatially on that same desk, all without picking up a phone, switching apps, or touching a keyboard. The name is a play on the word "noodling": thinking something through. It is not a cooking application.
Why Snap Spectacles and not another platform?
Snap Spectacles Gen 5 was the right platform because of its full waveguide display, spatial computing SDK, and hand-tracking-only input model. The constraint of no keyboard was not a limitation to work around: it became the design principle. Voice-first and gesture-first input is faster for the right tasks, and the hardware forced us to design an interaction model that could not have existed on a phone or laptop. The spatial SDK let us anchor outputs to real-world surfaces in a way that made the physical and digital share one logic.
What does winning MIT Reality Hack mean for a brand briefing spatial AI work?
It means the studio has built a production spatial AI experience under real pressure, on real hardware, with real judges who know the space. MIT Reality Hack attracts serious researchers, platform engineers, and spatial computing practitioners. Winning in the spatial AI category with a Snap-sponsored prize means the interaction model and technical execution both stood up to that scrutiny. For a brand commissioning wearable AR or spatial AI work, that is a meaningfully different reference point from a demo built in a controlled studio environment.
If you are new to MIT Reality Hack and want context on what the event is and why winning matters for wearable AR, see What is MIT Reality Hack?
Insights newsletter
Smart glasses, AR campaigns, spatial computing.
Straight to your inbox. No noise.
SubscribeWant to explore spatial AI for your brand?
Tell us the user moment you are designing for. We will tell you whether spatial AI can remove the Toggle Tax from it.
Start a project